名词
这些名词下面会用到,提前过一下。
- index:类似数据库,是存储、索引数据的地方。
- shard:index 由 shard 组成,一个 primary shard,其他是 replica shard。
- segment:shard 包含 segment,segment 中是倒排索引,它是不可变的;segment 内的文档数量的上限是
2^31。 - 倒排索引:倒排索引是 Lucene 中用于使数据可搜索的数据结构。
- translog:记录文档索引和删除操作的日志。Lucene 在每次 commit 之后把数据持久化到磁盘,但是 commit 操作代价很大,所以不能在每次数据变更之后执行 commit。Elasticsearch 为防止宕机造成数据丢失,每次写入数据时会同步写到
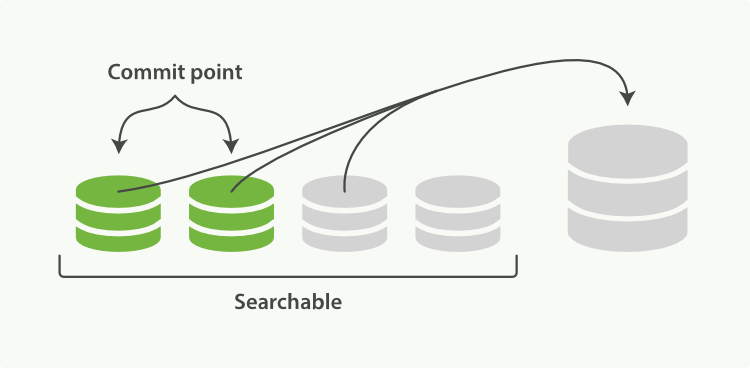
buffer和translog,在 flush 操作时把数据持久化。 - commit point:列出所有已知 segment 的文件。
index -> shard -> segment -> 倒排索引
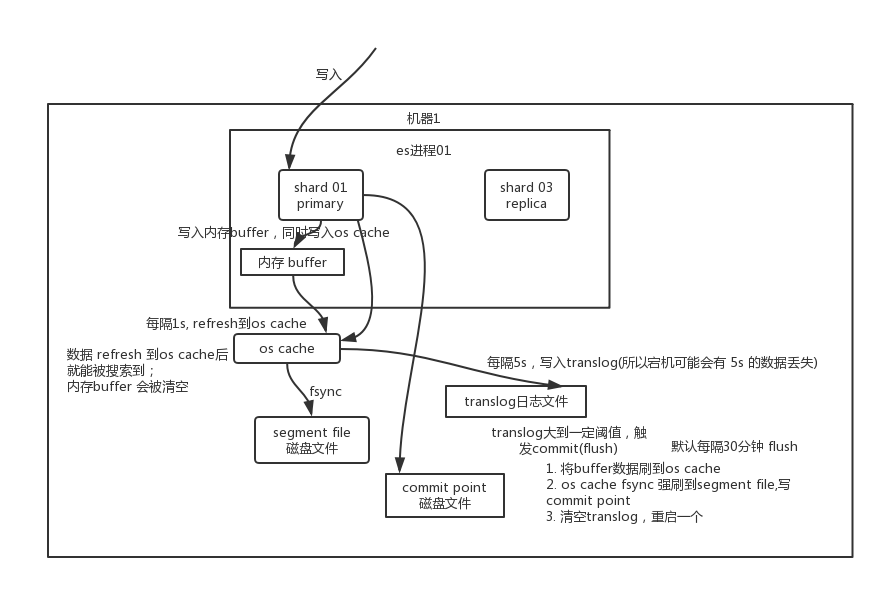
写数据
-
先写入内存
buffer(这时数据是搜索不到的),同时将数据写入translog日志文件。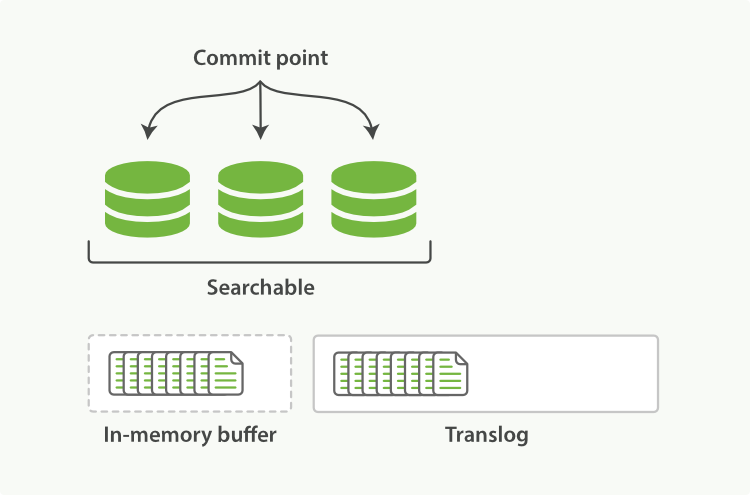
- 如果
buffer快满了或者到一定时间(1秒),将buffer数据 refresh 到os cache即操作系统缓存。这时数据就可以被搜索到了:- buffer 的文档被写入到一个新的 segment 中;
- segment 被打开以供搜索;
- 内存 buffer 清空。
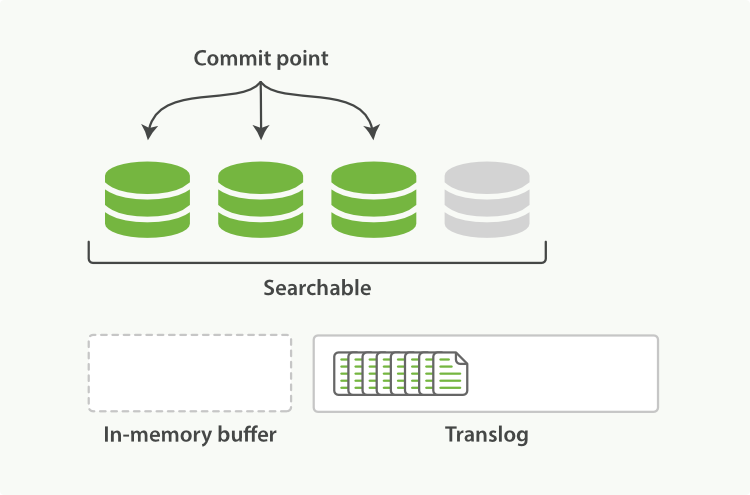
- 当
translog达到一定长度的时候,就会触发 flush 操作(flush 完成了 Lucene 的commit操作):- 第一步将
buffer中现有数据refresh到os cache中去,清空buffer; - 然后,将一个
commit point写入磁盘文件,同时强行将os cache中目前所有的数据都 fsync 到磁盘文件中去; - 最后清空现有
translog日志文件并重建一个。
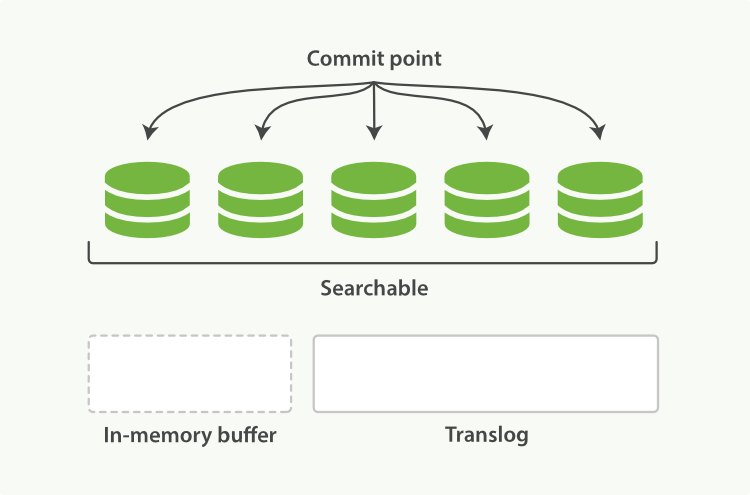
- 第一步将
整个过程如图:
删除和更新
由于 segment 是不可变的,索引删除的时候既不能把文档从 segment 删除,也不能修改 segment 反映文档的更新。
- 删除操作,会生成一个
.del文件,commit point会包含这个.del文件。.del文件将文档标识为deleted状态,在结果返回前从结果集中删除。 - 更新操作,会将原来的文档标识为
deleted状态,然后新写入一条数据。查询时两个文档有可能都被索引到,但是被标记为删除的文档会被从结果集删除。
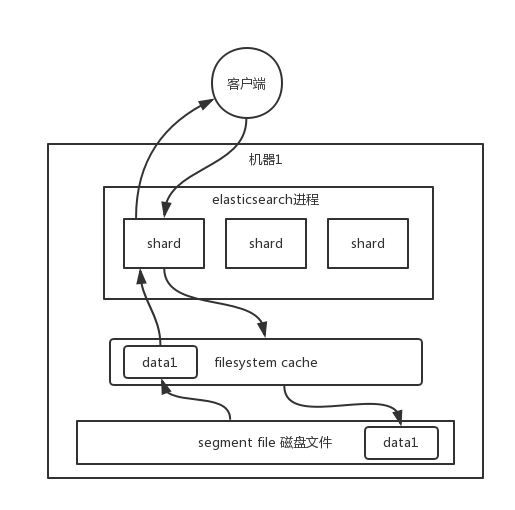
查询
查询的时候操作系统会将磁盘文件里的数据自动缓存到 filesystem cache。Elasticsearch 严重依赖于底层的 filesystem cache,如果给 filesystem cache 很大,可以容纳所有的 index、segment 等文件,那么搜索的时候就基本都是走内存的,性能会非常高;反之,搜索速度并不会很快。
segment 合并
buffer 每 refresh 一次,就会产生一个 segment(默认情况下是 1 秒钟产生一个),这样 segment 会越来越多,此时会定期执行 merge。
- 将多个
segment合并成一个,并将新的segment写入磁盘; - 新增一个
commit point,标识所有新的segment; - 新的
segment被打开供搜索使用; - 删除旧的
segment。