1. 索引的优点
- 索引可以减少扫描的数据量。
- 索引和避免排序和建立临时表。
- 索引可以将随机IO变为
顺序IO。
2. 索引的选择性
索引的选择性是索引列不重复的值和表记录总数(n)的比值,范围在 1/n 到 1 之间。选择性越高查询效率就越高,因为选择性高的索引可以在查询时过滤掉更多的行。唯一索引的选择性是 1,所以性能也是最好的。
如何选择索引的列顺序至关重要:
- 将选择性高的列放在索引的前面;
- 将
范围查询的列放在索引的后面。
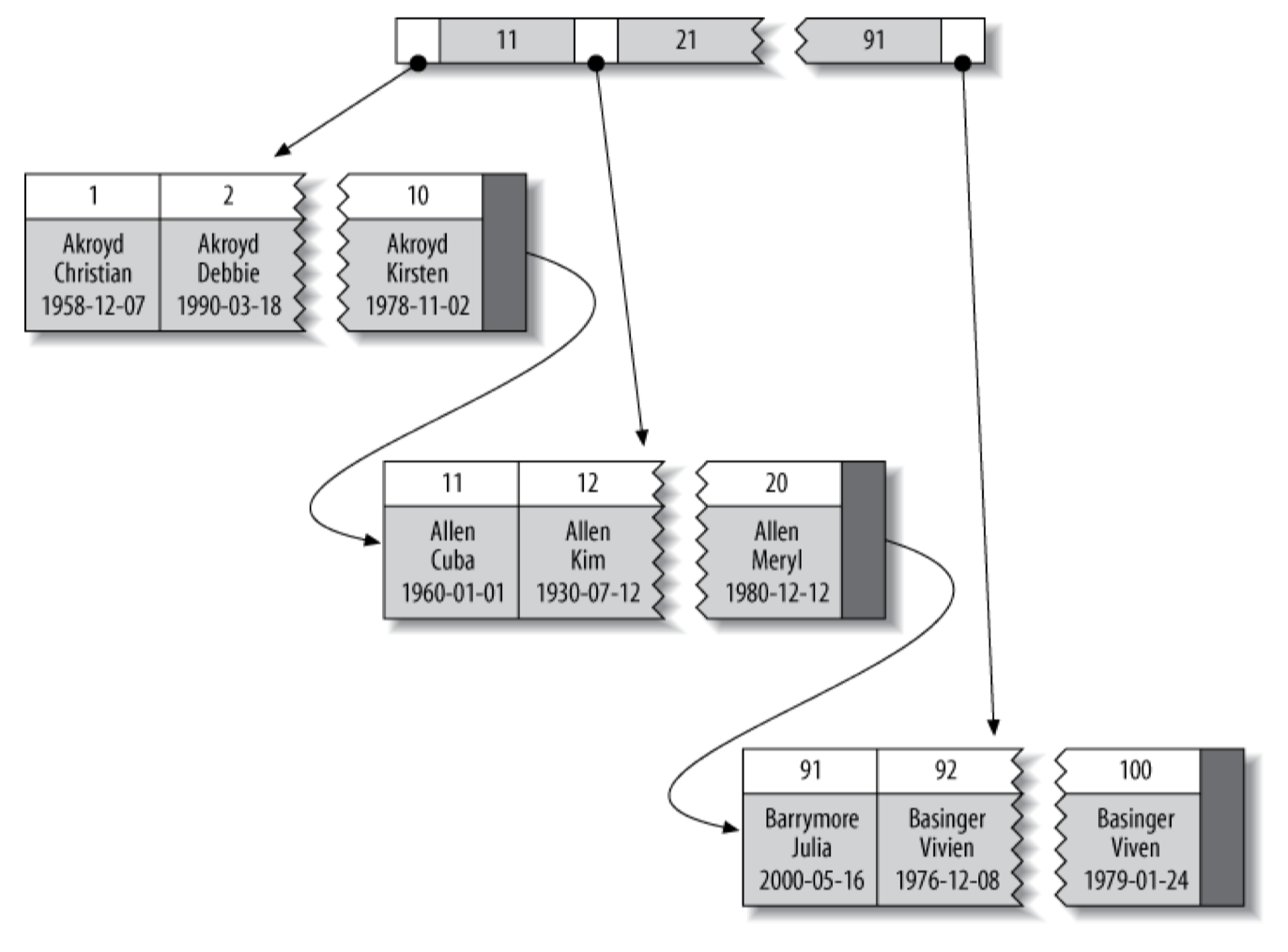
3. 聚簇索引
聚簇索引不是一种单独的索引类型,而是一种数据的存储方式。
当表有聚簇索引时,它的数据行存放在索引的叶子页中。聚簇表示数据行和相邻的键值紧凑地储存在一起。由于无法同时把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。
InnoDB 通过主键聚集数据。
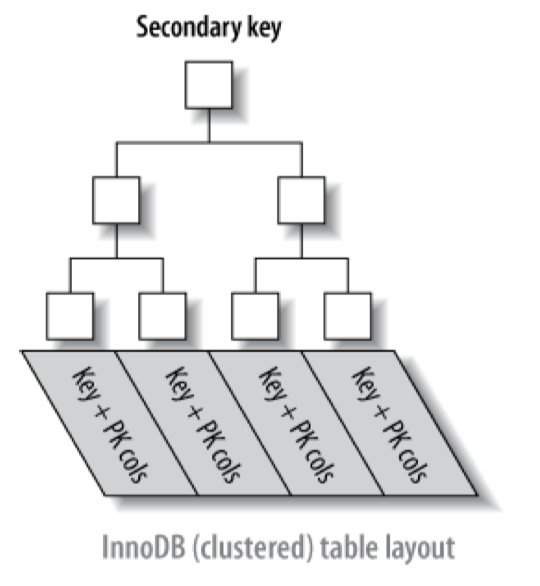
4. 二级索引
二级索引指的是非聚簇索引。
- 二级索引的叶子节点中包含了引用行的
主键列。 - 二级索引需要
两次索引查找。因为二级索引保存的不是指向行的物理位置的指针,而是行的主键值。
5. 覆盖索引
覆盖索引:索引包含所有需要查询的字段的值。只有B-Tree索引能实现覆盖索引。
- 索引列一般小于数据列,如果只需要读取索引,能极大减少数据访问量;
- 索引按照列值顺序排序,能减少随机IO访问。
6. 使用索引扫描做排序
MySQL生成有序结果有两种做法:
- 对查询结果做排序操作;
- 按索引顺序扫描(
explain命令的type值为index时)。
如果要用索引排序要满足以下条件:
- 索引的
列顺序和ORDER BY子句的列顺序完全一致; - 排序列的
排序方向完全一致; - 关联多表时,
ORDER BY子句全部为第一个表,并且符合上面两个要求; - 特殊情况:排序前导列为常数,可以不满足
左前缀要求,但是剩余的列也必须顺序一致。
7. B-Tree 索引匹配
B-Tree 索引对以下查询有效(列顺序必须符合最左匹配):
- 全值匹配:和索引的所有列进行匹配。
- 匹配最左前缀。
- 匹配范围值。
- 精确匹配某一列,并范围匹配另一列。
限制:
- 索引列不能是表达式的一部分或是函数的参数;
- 必须从索引的
最左列开始; - 不能跳过索引中的列;
- 避免索引列的
隐式转型; - 如果查询中有某个列的
范围查询,则其右边的列都无法使用索引优化查找。