原文来自Using pipelining to speedup Redis queries
Request/Response 和 RTT
Redis 是使用 C/S 模式的服务器,并使用名为 Request/Response 协议。
这意味着通常一个请求是通过以下几步实现的:
- 客户端发送一个查询到服务端,然后等待从套接字中读取(通常是阻塞模式)服务器端的响应。
- 服务器端处理命令,然后把响应发送给客户端。
如发送 4 个顺序的命令就像下面这样:
- Client: INCR X
- Server: 1
- Client: INCR X
- Server: 2
- Client: INCR X
- Server: 3
- Client: INCR X
- Server: 4
客户端和服务器端通过网络连接,这个连接可能很快(回环接口 loopback interface)也可能很慢(通过互联网连接,两台机器间有多跳)。无论网络延迟如何,客户端发送请求到服务器端、服务器端发送响应到客户端,都要花费一定时间。
这段时间称之为 RTT (Round Trip Time 往返时间)。当客户端需要连续执行一批请求的时候很容易看出它对于性能的影响(如往 list 添加一批元素,或往数据库添加很多 key)。如 RTT 是 250 毫秒(可能是通过互联网的连接),就算服务器能每秒处理 100K 的请求,在这种情况下一秒也只能处理 4 个。
如果使用的是回环接口,RTT 很短(例如我的服务器 ping 127.0.0.1 花费 0,044 毫秒),但如果要连续处理一批命令的话还是太长了。
幸运的是有种方法可以改善它。
Redis 管道
一个实现了 Request/Response 协议的服务器可以在客户端还没有读取老请求的情况下接着处理新请求。这样就可以一次发送多个请求到服务器而无需等待响应,并且在最终一次性读取响应。
这就叫做管道,这种技术在过去几十年间已经被广泛运用了。例如许多 POP3 协议实现了这种特性,大大加速了从服务器下载邮件的速度。
Redis 很早就实现了管道,所以无论你使用的是哪个版本都可以使用它。下面是一个使用 netcat 的例子:
$ (printf "PING\r\nPING\r\nPING\r\n"; sleep 1) | nc localhost 6379
+PONG
+PONG
+PONG
在发送 3 个命令后只等待了 1 个往返时间(RTT),而不是 4 个。
为了更清楚地解释,第一个例子在使用管道之后,会像下面这样:
- Client: INCR X
- Client: INCR X
- Client: INCR X
- Client: INCR X
- Server: 1
- Server: 2
- Server: 3
- Server: 4
注意:如果客户端用管道发送命令,服务器端会强制把响应放在内存的一个队列里。所以如果你要使用管道发送大量命令,最好批量发送命令,并把每批的数量控制在一个合理的范围内。例如发送 10K 命令,读取响应,然后再发送 10K,以此类推。速度上几乎一样,但是使用的内存最多只会是那 10K 命令的响应。
这不仅关于 RTT
管道不仅能减少往返时间造成的延迟,还能极大提高一个给定 Redis 服务器每秒能处理的命令数量。这是基于一个事实,在不使用管道处理每个命令的时候,获取数据和生成响应的开销很小,但是处理套接字 I/O 开销很大。因为它包括调用系统级的方法 read() 和 write(),这意味着用户和系统的切换。上下文切换对速度影响非常大。
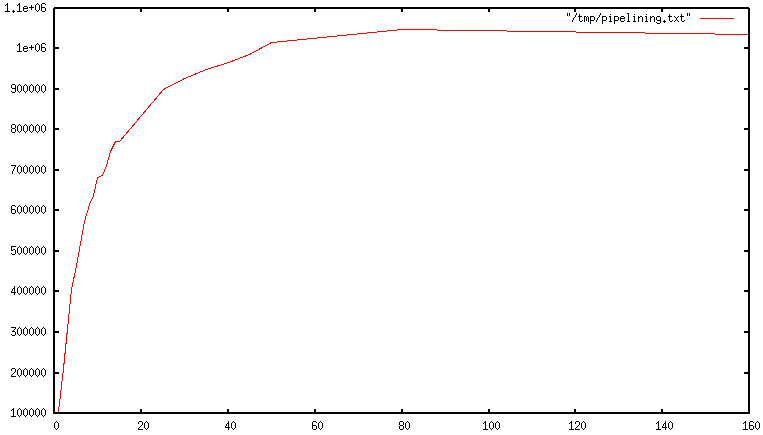
而在使用管道时,读取许多命令仅需调用一次 read() ,发送响应时仅需调用一次 `write()。正因为如此,一开始时每秒处理的命令数量是随着管道使用时间线性增长的,最终会达到不使用管道时的基线的 10 倍。如下图:
真实的例子
下面将看到一个支持管道的 Redis Ruby 客户端测试管道带来的速度提升:
require 'rubygems'
require 'redis'
def bench(descr)
start = Time.now
yield
puts "#{descr} #{Time.now-start} seconds"
end
def without_pipelining
r = Redis.new
10000.times {
r.ping
}
end
def with_pipelining
r = Redis.new
r.pipelined {
10000.times {
r.ping
}
}
end
bench("without pipelining") {
without_pipelining
}
bench("with pipelining") {
with_pipelining
}
在 Mac OS X 系统上,通过回环接口运行上述脚本,会得到数据如下:
without pipelining 1.185238 seconds
with pipelining 0.250783 seconds
可以看到使用管道仅使用了五分之一的时间。
管道 VS 脚本
如果使用 Redis 脚本(Redis Scripting), 可以发现很多使用管道的用例(需要在服务器端做很多工作的)在使用脚本之后,效率更高了。脚本的一大优点是它可以让读写数据的延迟最小,读、写、计算都会非常快(管道在这种场景下没有帮助,因为客户端需要在做写操作之前得到读操作的响应)。
有时应用可能要在管道中发送 EVAL 或 EVALSHA 命令。这完全是可能的,而且 Redis 的 SCRIPT LOAD 命令显示地支持它(它保证 EVALSHA 命令能被没有失败风险地调用)。