名词
- node:一个运行中的 Elasticsearch 实例称为一个节点。
- shard:Elasticsearch 的分片就是 Lucene 的 index,Lucene 的 index 包含多个 segment。
节点
集群模式下 Elasticsearch 会选举一个节点为主节点(master)。主节点负责维护索引元数据、增加、删除节点、在节点间分配分片等操作,不会涉及文档级别的操作。
- 主节点宕机后会重新选举。
- 当有节点加入集群或从集群中删除节点时,集群将会重新分布数据。
- 请求可以发给任意节点(包括主节点),每个节点都能把请求转发给文档所在节点,并能负责从各个节点收集数据最终转发给用户。
每个节点可能有一个或多个功能(配置项):
- 可被选举为主节点(master-eligible node):节点有资格被选为主节点。这是默认配置。
- 数据节点(data node):节点存放数据并会操作数据。默认配置。
- 消化节点(ingest node):索引文档之前预处理节点。已过时。
- 部落节点(tribe node):连接多个集群进行查询的节点。
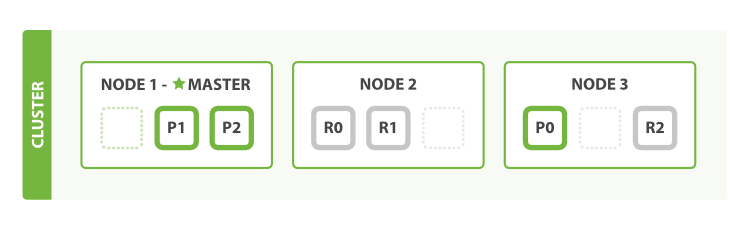
分片
索引是指向一个或多个物理分片(shard)的逻辑命名空间。
- 分片包括一个主分片(primary shard)和多个副本分片(replica shard)。
- 主分片的数目在索引创建时就已经确定了下来。
- 索引的所有文档都存放在主分片(最多能存储
Integer.MAX_VALUE - 128个文档),副本分片只是主分片的拷贝。 - 主分片宕机后会由一个副本分片取代。
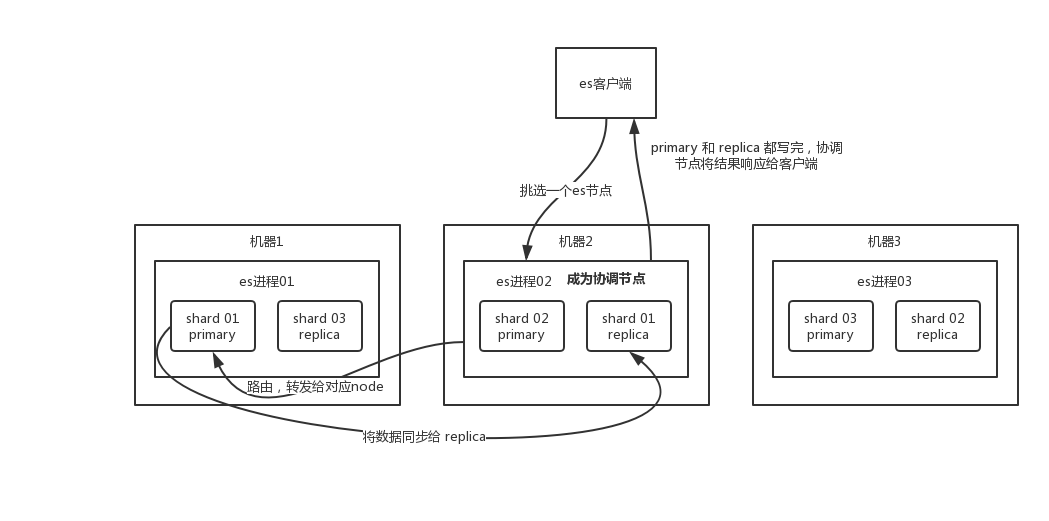
写入
- 客户端选择一个 node 发送请求过去,这个 node 就是 coordinating node(协调节点)。
- coordinating node 对 document 进行路由,将请求转发给对应的 node(primary shard)。
- primary shard 处理请求,然后将数据同步到 replica node。
- coordinating node 如果发现 primary node 和所有 replica node 都完成之后,就返回响应结果给客户端。
读取
根据文档 id 读取
- 客户端发送请求到任意一个节点,成为协调节点。
- 协调节点对文档 id 进行哈希路由,将请求转发到对应的节点,此时会使用 round-robin 随机轮询算法,在主分片以及其所有副本分片中随机选择一个,让读请求负载均衡。
- 接收请求的节点返回文档给协调节点。
- 协调节点返回文档给客户端。
全文检索
- 客户端发送请求到一个协调节点。
- 协调节点将搜索请求转发到所有的分片。
- 查询阶段:每个分片将自己的搜索结果(即文档 id)返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。
- 获取阶段:接着由协调节点根据文档 id 去各个节点上拉取实际的文档数据,最终返回给客户端。